Wat mijn échte ChatGPT-data liet zien (en waarom mijn eerste analyse niet klopte)
Kortgeleden vroeg ik ChatGPT een analyse te doen van mijn AI-gebruik. Getriggerd door een Linkedin-bericht van Huib Koeleman, ging ik dus ook aan de slag met de prompt: “Kan je mij een analyse geven van hoe ik chatgpt vooral gebruik? Kan je hier een mooie grafiek of een wiel van maken? Het antwoord zag er goed uit. Ik dacht: ja, dit zal wel kloppen. Maar wat blijkt? Het klopt niet. Ik deed de aanname dat ChatGPT daadwerkelijk al mijn prompts analyseerde. Dit maakte me nieuwsgierig. Als dit niet klopt, hoe analyseer je je AI-gebruik dan wél goed? En wat levert dat op als je het serieus aanpakt?
We werken dagelijks met aannames. Over doelgroepen, over wat werkt, over hoe mensen informatie gebruiken. Te weinig duiken we echt de data in. En zo ook rondom AI-gebruik: “Ik gebruik ChatGPT vooral voor…” is meestal een zin die gebaseerd is op gevoel, niet op data. In eerste instantie bleek mijn prompt dus te kort door de bocht. Dat motiveerde mij om er echt in te duiken, niet op basis van een aanname, maar op basis van de echte data.
Waarom klopte de analyse niet?
Nadat ik mijn analyse had gedeeld op Linkedin, bleven er vragen over. Ik stelde een verdiepende vraag om zicht te krijgen op mijn gebruik in de afgelopen periode. Toen kreeg ik als antwoord dat ChatGPT helemaal mijn chats niet kan lezen. “Ik heb geen toegang tot je chatgeschiedenis per datum, map of maand en kan geen echte logs analyseren.” Uh..hoe kan ik dan die analyse hebben gekregen? Ik ging ervan uit dat ChatGPT mijn hele gebruiksgeschiedenis meenam. De analyse keek echter alleen naar het huidige gesprek (en een soort model van gebruikerstypen). Mijn eerdere chats, vragen en patronen zaten er helemaal niet in. De uitkomsten waren dus gebaseerd op een verkeerde aanname, waardoor de analyse niet betrouwbaar genoeg was.
Juist omdat AI zo overtuigend kan klinken, is het risico groot dat je een analyse accepteert die logisch voelt, maar niet klopt. Een belangrijke les dus.
Nu wilde ik natuurlijk weten hoe ik de analyse wel kan doen. Dat is gelukt! Met één prompt ben je er niet. Voor (bijna) iedereen is dit ook te doen, maar niet in 2 minuten. Graag neem ik je mee in hoe het werkt, en daarna deel ik dan ook mijn echte data en inzichten.
De echte data analyseren
Stap 1: download data en verklein bestand in Python
Via ChatGPT kun je je volledige data-export downloaden. Wat je dan krijgt, is geen overzichtelijk document, maar een groot .json-bestand. Ik wist globaal wat dat was – een gestructureerd databestand – maar ik had er zelf nog nooit mee gewerkt. Het bestand bleek bovendien te groot om zomaar te uploaden en te analyseren in ChatGPT. ChatGPT stelde daarop voor om Python te gebruiken om het bestand te verkleinen.
Ik had wel van Python gehoord, maar er niet eerder zelf mee gewerkt. Ik wist dat het iets met programmeren en codes is. Leuke kans dus om voor dit vraagstuk Python te proberen. Met behulp van code en aanwijzingen van ChatGPT heb ik het bestand stap voor stap verkleind, met één duidelijk doel: alleen mijn eigen prompts overhouden en het bestand dus verkleinen zodat het wel door ChatGPT geanalyseerd kan worden. Handig om te weten: je hoeft Python niet echt te begrijpen om dit te doen. Het gaat erom dat je de data terugbrengt tot iets wat analyseerbaar is en ChatGPT zegt je welke stappen je daarvoor moet nemen.
Zodra dat gelukt was (redelijk soepel), kon de verdere analyse volledig in ChatGPT plaatsvinden.
Stap 2: inhoudelijke analyse en visualisatie
Met het verkleinde bestand begon het inhoudelijke werk pas echt. De eerste stap was categoriseren: welke soorten vragen stel ik eigenlijk? Voorgestelde categorieën heb ik aangescherpt, zodat ze helder zijn. Te abstracte categorieën leverden weinig op. Pas toen ik categorieën koos die aansloten op hoe ik werk en denk, werd het interessant.
Ik gebruikte onderstaande prompt die Sandra de Blaeij heeft gemaakt om de data te analyseren.
-
Bekijk de prompt
Maak een analyse van hoe ik AI (ChatGPT) vooral gebruik. Maak daarna een radarprofiel (schaal 1–10) én een verdeling in percentages.
Werkwijze
A) Analyse
• Beschrijf per categorie in 4–6 bullets:
• wat ik hier precies mee doe
• welke type vragen/outputs hierbij horen (2–3 voorbeelden)
• welke kracht dit laat zien (1 zin)
• waar de valkuil zit (1 zin)
B) Percentages
• Geef een schatting van de verdeling in percentages die optelt tot 100%.
• Leg per categorie in 1 zin uit waarom je dat percentage kiest.
C) Radarprofiel (1–10)
• Geef per categorie een score 1–10 op basis van dominantie/sterkte in mijn gebruik
• Licht elke score toe in 1 zin.
D) Outputvorm
1. Lever eerst één overzichtstabel:
categorie | % | score (1–10) | kernachtige toelichting
2. Sluit af met:
• 1 zin: “In één zin: zo gebruik ik AI…”
• 3 bullets: “mijn top-3 krachten”
• 2 bullets: “waar ik AI nog slimmer kan inzetten”
Daarna werd het leuk om te visualiseren.
Ik stelde ChatGPT daarbij onder andere de volgende vragen:
- Maak een overzicht van het aantal prompts per maand van afgelopen jaar.
- Laat zien hoe de verdeling van categorieën zich ontwikkelt over de tijd.
- Maak een taartdiagram van alle data, exclusief korte interacties.
- Vergelijk het totale gebruik met alleen de laatste drie maanden.
De grafieken nam ik niet klakkeloos aan. Ik vroeg door: waarom ziet dit er zo uit? Wat zit hier niet in? Minstens zo belangrijk was het filteren van ‘procesruis’. Niet elke prompt is een nieuwe inhoudelijke vraag. Korte reacties, bijsturingen en correcties zeggen vooral iets over interactie, niet over focus. Door die eruit te halen, bleef over wat ik echt wilde analyseren: inhoudelijke prompts.
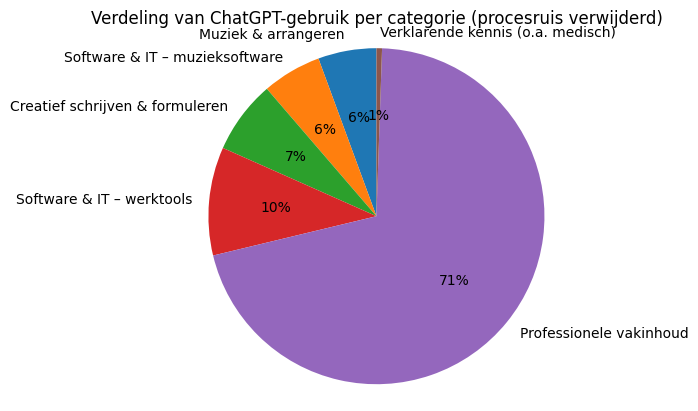
Jaarverdeling per categorie
- Professionele vakinhoud: 71%
Ik gebruik ChatGPT vooral als denkpartner in mijn professionele werk: om structuur aan te brengen, redeneringen aan te scherpen, keuzes expliciet te maken en aannames te toetsen. Dit is geen oriëntatie of inspiratie, maar verdiepend denkwerk midden in het proces om te komen tot een advies, voorstel, strategie of om afweging goed te onderbouwen.
- Software & IT (werktools): 10%
Hier gaat het om praktische, functionele vragen over software, zoals Microsoft, Canva of Teams. “je bent netwerkbeheerder van microsoft. Je wilt zorgen dat gasten ook bestanden in een Teams kunnen downloaden. Op welke plek ga je deze instelling aanpassen?”
- Creatief schrijven & formuleren: 7%
Hier gaat het niet om ‘creatief schrijven’, maar om aanscherpen en herschrijven. “kan je deze zin soepeler laten lopen?” “kan je dit vertalen?””kan je dit meer als storytelling brengen?”
- Software & IT (muzieksoftware): 6%
Hier zit echt mijn leerproces van muziekprogramma’s die ik gebruik (Finale, Garageband en Dorico 6). Het zijn veel korte, opeenvolgende vragen die samen één technisch probleem oplossen. “ik gebruik finale en een midi keyboard, hoe speel ik nu geluid af want ik hoor niets”
- Muziek & arrangeren: 6%
Mijn ambitie dit jaar is om te leren arrangeren voor mijn band. Hier gebruik ik ChatGPT als leer- en sparringpartner. “ik heb sopraan sax, tenor en alt, daarnaast 2 trompetten, trombone, tuba. Wie kan de melodie spelen? Welke overwegingen maak ik hierin?”
- Verklarende kennis (o.a. medisch): 1%
Dit is incidenteel, feitelijk, duidelijk informatief. “Kan je uitleggen wat ernstige thyreotoxicose (hyperthyreoï) is?” Dat ‘verklarende kennis’ in mijn analyse maar 1% blijkt te zijn, verraste me. Het voelt alsof ik dit vaker doe. ChatGPT geeft aan dat dit bij mij vaak verweven in grotere denkvragen, of zijn het korte interacties die in de analyse minder zwaar meewegen.
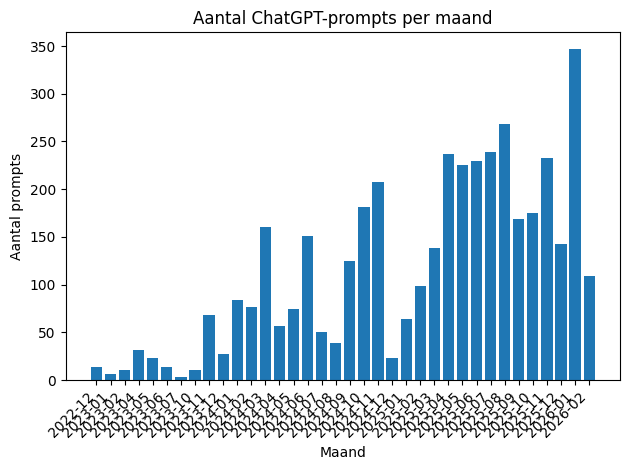
Ontwikkeling van gebruik
Na dit overzicht van categorieën was ik ook benieuwd naar het verloop in de tijd. Het aantal prompts per maand liet zien hoe mijn gebruik zich ontwikkelde: van incidenteel naar structureler, in duidelijke fases.
Een andere leuke bevinding vond ik de verschuiving in de categorieën. Door per maand te kijken welke soorten vragen dominant waren, werd zichtbaar hoe mijn focus veranderde. De analyse van alleen de laatste drie maanden liet bovendien een ander beeld zien dan het gemiddelde over het hele jaar.
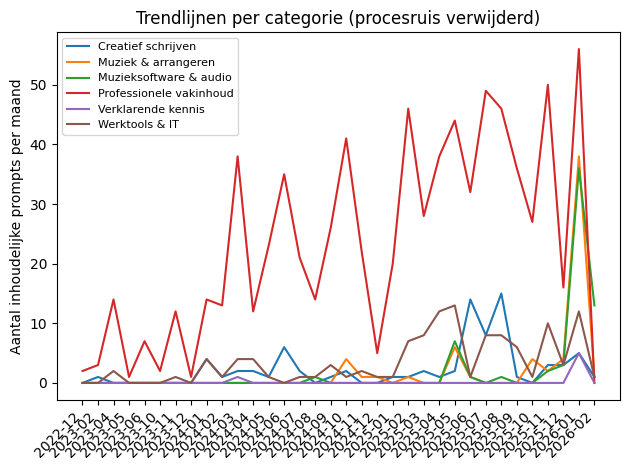
Door de categorieën per maand te bekijken, werd zichtbaar dat mijn AI-gebruik geen vast patroon heeft, maar meebeweegt met projecten en interesses. Best logisch ook.
En ik was nog nieuwsgierig of mijn laatste drie maanden een heel ander beeld geeft. Dat leverde onderstaand taartdiagram op.
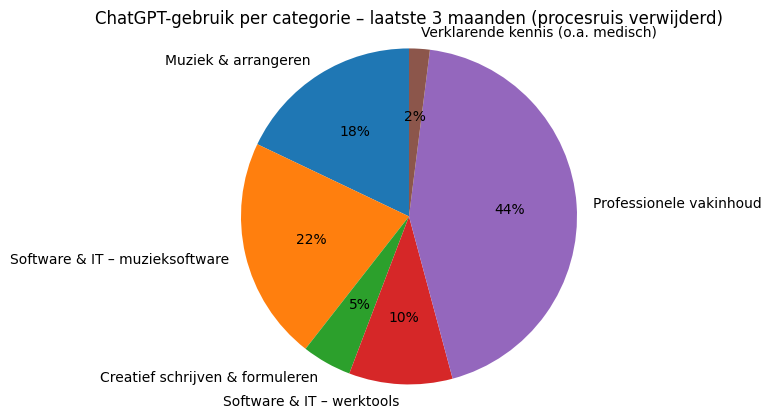
“De afgelopen 3 maanden gebruik je ChatGPT veel breder: naast professioneel denkwerk vooral intensief voor muziek en muzieksoftware.”
Stap 3: inzichten op een rij
Zo leverde dit een preciezer beeld op van hoe ik ChatGPT daadwerkelijk inzet. In het begin gebruikte ik ChatGPT vooral om dingen uit te zoeken en helder te krijgen. Gaandeweg is dat veranderd. Mijn gebruik is verschoven van vooral verklarend en verkennend naar inhoudelijk verdiepend en toetsend. Ik zet het nu vaker in midden in mijn denkproces, om structuur aan te brengen, aannames te toetsen en mijn redenering scherper te maken. Naast natuurlijk de praktische en lerende kant in mijn muzikale reis.
Stap 4: vooruitkijken
Ik was ook nog even nieuwsgierig naar waar kansen voor mij liggen. Welke toepassing laat ik nog liggen? Chat geeft aan dat er een kans ligt in het expliciet verkennen van aannames, invalshoeken en mogelijke richtingen voordat ik me vastleg. Of in het voorbereiden van gesprekken. Daarnaast kansen in meer keuzeverkenning: niet om meer ideeën te krijgen, maar om bewuster te kiezen. En verder in het explicieter inzetten van AI als tegenstem.
Met name dat laatste vind ik interessant. Gelijk gekeken naar prompts die erbij passen “Welke keuzes maak ik hier, zonder ze expliciet te benoemen?” “Welke opties laat ik nu bewust of onbewust liggen?” “Wat zou iemand met een heel andere achtergrond hier meteen opmerken?” “Welke uitkomst hoop ik stiekem dat hieruit komt?”
Los hiervan zie ik voor mezelf ook een reden om andere taalmodellen meer te verkennen, zoals Claude en Gemini, onder meer vanwege geopolitieke overwegingen. (Zie hiervoor deze relevante video op instagram van Rutger Bregman.)
Wat blijft er overeind van de eerste analyse?
Terugkijkend zat mijn eerste ChatGPT-analyse er niet volledig naast. Een deel van wat werd geschetst, herkende ik wel. Maar juist dat maakte het misleidend. De analyse bleek te algemeen, te statisch en gebaseerd op aannames over data die er niet was. Misschien wel een beetje als een horoscoop, waar je altijd iets in herkend?
Deze uitleg van ChatGPT verklaart dit ook: “Als ChatGPT maak ik gebruikerstypen door patronen in vraagvormen te herkennen, die te vergelijken met veelvoorkomende interacties, en ontbrekende data aan te vullen met plausibele aannames.”
De verschillen heb ik op een rij gezet in deze tabel
| Aspect | Oorspronkelijke analyse (op aannames) | Analyse op basis van echte data |
| Databron | Huidige chat + algemeen gebruiksmodel | Eigen prompts uit volledige data-export |
| Scope | Momentopname | Volledig gebruik + ontwikkeling over tijd |
| Balans tussen categorieën | Relatief gelijkmatig verdeeld | Sterk geconcentreerd op professioneel denkwerk |
| Creatief gebruik | Lijkt groot en prominent | Ondersteunend, niet dominant |
| Reflectie | Geïnterpreteerd als zelfontwikkeling | Vooral inhoudelijk toetsen en aanscherpen |
| Praktische vragen | Belangrijke categorie | Aanwezig, maar duidelijk ondersteunend |
| Ontwikkeling in de tijd | Ontbreekt volledig | Cruciaal inzicht: fases en verschuivingen |
| Herkenbaarheid | Hoog (“dit zou kunnen kloppen”) | Hoog, maar nu onderbouwd |
| Nauwkeurigheid | Plausibel maar te algemeen | Precies, contextueel en fase-afhankelijk |
| Belangrijkste beperking | Verkeerde aanname over data | Bekende en benoemde datagrenzen |
De eerste analyse zat er vooral naast in de verhoudingen van de categorieën, en de categorieën waren ook niet precies genoeg. Als ik dan toch percentages vergelijk van eerste analyse (aannames) en echte data, dan zie je onderstaande verschuiving (met dus wel de kanttekening dat andere categorieën passender blijken):
| Categorie (oorspronkelijk) | Eerste analyse (aannames) | Echte data (hergeprojecteerd) | Afwijking |
| Analyse & inzicht krijgen | ±30% | ±50–55% | 🔼 sterk onderschat |
| Creatief denken & schrijven | ±25% | ±12–15% | 🔽 overschat |
| Praktische hulp & uitleg | ±20% | ±15–18% | ≈ redelijk |
| Reflectie & zelfontwikkeling | ±15% | ±5–8% | 🔽 sterk overschat |
| Oriëntatie & inspiratie | ±10% | ±3–5% | 🔽 sterk overschat |
Kortom, het geeft wel echt een ander beeld als je de echte data gebruikt. De eerste analyse beschreef een logisch verhaal, de data-analyse beschrijft daadwerkelijk gedrag – inclusief nuance, verschuiving en context. En hierbij kon ik bovendien wel echte prompts terughalen, in plaats van prompts die ik helemaal niet had gebruikt.
En nu jij
Je hoeft dit proces niet één-op-één te volgen (wel als je het leuk lijkt natuurlijk). Maar een paar dingen zijn het proberen waard:
- Check je aannames over hoe je AI gebruikt. [EP4]
- Zorg daarbij dat je analyse gebaseerd is op de juiste data. Controleer dus welke data jouw AI gebruikt voor de analyse.
- Kijk niet alleen naar momentopnames, maar ook naar ontwikkeling in de tijd.
- Zoek de diepgang. Als je bijvoorbeeld vraagt naar een lijstje met voor- en nadelen, krijg je vaak 5 voordelen en 5 nadelen. Pas als je doorvraagt naar ALLE voor- en nadelen krijg je een volledige lijst. Hiermee kan je vervolgens een goede selectie te maken.
- Verbreed je blik en gebruik ook andere AI-systemen. Vergelijk wat dat oplevert.
En misschien wel het belangrijkste: AI kan veel. Maar zonder scherpe vragen en goede data kan het ook overtuigend ongelijk hebben. Wijs me vooral op wat ik over het hoofd zie. Dit is mijn analyse, met mijn keuzes en vast ook mijn blinde vlekken.
Veel speelplezier met de data en AI-ontwikkelingen.
Roosmarijn Busch
Voetnoot: ik gebruik bij het werken met AI geen gevoelige bedrijfsdata en anonimiseer data.
Zie ook: